GLM-5.2 Free: Run It in Your Browser, No API Key (2026)
Use GLM-5.2 free with no API key — run it in your browser via SciClaw · Mira free credits, plus benchmarks, cost vs GPT-5.5, and a first-hand test.
To try GLM-5.2 free, you can sign up for SciClaw · Mira and use free credits to run it in your browser — no API key or local setup.
GLM-5.2 launched on June 13, 2026 from Z.ai (Zhipu) — a 1M-token context window, coding-first, MIT open weights, beating GPT-5.5 on several long-horizon coding benchmarks at roughly one-sixth the cost. There's been a lot of discussion since launch, but many people get stuck on one practical question: how do you actually use it for free?
This guide answers that first, then breaks down — with first-hand testing — what GLM-5.2 is actually good at and who it's for.
By SciClaw · Mira · Last updated: 2026-06-17
How we sourced this: benchmark figures are taken from Z.ai's official release and third-party data such as llm-stats (fetched 2026-06-17) and cross-checked; the product test is in the "Case Study" section below.
Where You Can Use GLM-5.2 Free
Use it free on SciClaw · Mira Sign up and use free credits to run GLM-5.2 online in your browser — chat or assemble an agent, with no API key, no code, and no local setup. A good fit if you want to see real results quickly, or wire GLM-5.2 into an actual workflow.
Other routes (each with some friction):
| Route | API key? | Code? | Speed | Best for |
|---|---|---|---|---|
| SciClaw · Mira free credits | No | No | Fastest | Anyone wanting to just use it / wire it into a workflow |
| Z.ai official trial credits | Yes | Yes | Medium | Developers |
| Third-party playgrounds (Fireworks, Cloudflare Workers AI) | Varies | Some | Medium | Quick API testing |
| Self-host open weights | — | Yes | Slow | Teams with GPUs / data-privacy needs |
If you only want zero-signup, instant access to poke at the model, a third-party playground like Cloudflare Workers AI is the quickest path. SciClaw · Mira's value-add isn't raw model access — it's running GLM-5.2 inside a research-grade agent workflow (see the case study below).
What Is GLM-5.2? (30-second version)
GLM-5.2 is Z.ai's latest flagship, built for coding and agentic (autonomous) tasks.
| Spec | Detail |
|---|---|
| Released | June 13, 2026 |
| Architecture | Mixture-of-Experts (MoE), 744B total / 40B active params |
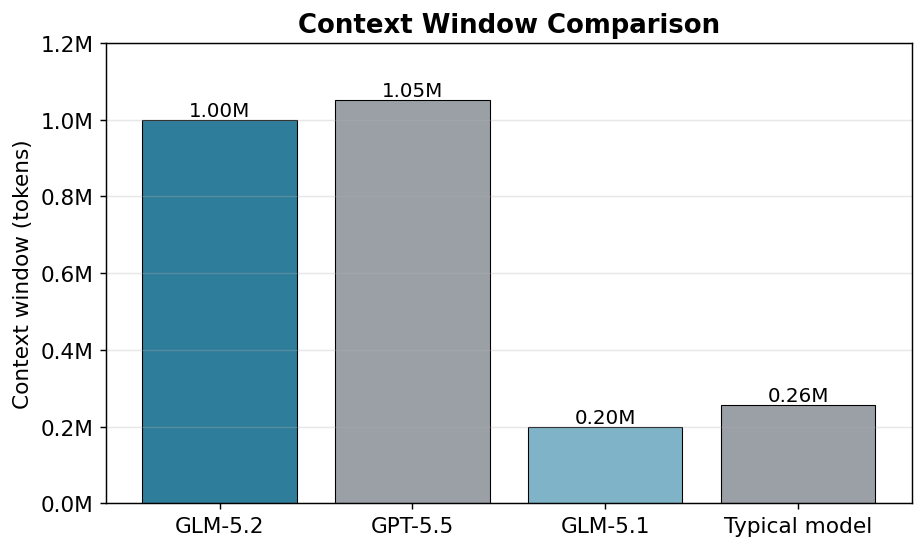
| Context window | 1,000,000 tokens (≈5× GLM-5.1) |
| Max output | 131,072 tokens |
| License | MIT (free commercial use, self-hostable) |
| Open weights | Hugging Face zai-org/GLM-5.2 |
| Day-one agent support | Claude Code, Cline, OpenCode, OpenClaw, Goose, Crush, Kilo |
In one line: an MIT-licensed, commercially usable model with a 1M-token context and coding benchmark scores that compete with leading closed models.
What GLM-5.2 Actually Offers
1. 1M-token long context
GLM-5.2 can take in ~1 million tokens at once — an entire mid-sized codebase, hundreds of pages of docs, a full long conversation — no chunking. It's the biggest jump over the previous generation (GLM-5.1 ≈ 200K).
2. Top-tier open-source coding scores
On the standard SWE-bench Pro benchmark, GLM-5.2 scores 62.1 — ahead of GPT-5.5's 58.6 (see llm-stats) — and hits 81.0 on the Terminal-Bench 2.1 tool-use benchmark. On long-horizon (multi-step, cross-file) coding it is also among the highest-scoring open models. Full scores in the "Review — Real Benchmarks" section below.
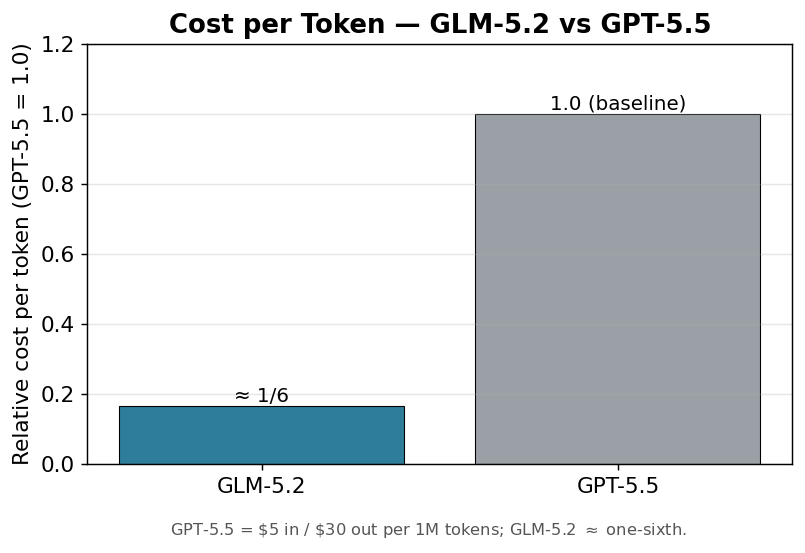
3. ~1/6 the cost
For comparable tasks vs GPT-5.5 ($5 input / $30 output per million tokens, see OpenAI's GPT-5.5 announcement), GLM-5.2 costs about one-sixth per token. On long tasks and high-volume agent runs, the difference compounds meaningfully.
4. MIT open weights — commercial & self-hostable
Weights are on Hugging Face under MIT — commercial use, modification, private deployment with near-zero restrictions. Key for data-sensitive teams.
5. Day-one agent ecosystem
Supported on launch day by Claude Code, Cline, OpenCode, OpenClaw, Goose, Crush and Kilo — so wiring it into an existing workflow takes almost no waiting. SciClaw · Mira also added GLM-5.2 in launch week; the "Case Study" below runs on it.
GLM-5.2 Review — Real Benchmarks
Scores taken from Z.ai's official release and cross-checked against public third-party data — sources: VentureBeat, llm-stats, CryptoBriefing (fetched 2026-06-17; figures may change as official numbers update):
| Benchmark | GLM-5.2 score | Type |
|---|---|---|
| SWE-bench Pro | 62.1 | Standard coding |
| Terminal-Bench 2.1 | 81.0 | Terminal / tool use |
| FrontierSWE | 74.4% | Long-horizon coding |
| PostTrainBench | 34.3% | Long-horizon |
| SWE-Marathon | 13.0% | Long-horizon |
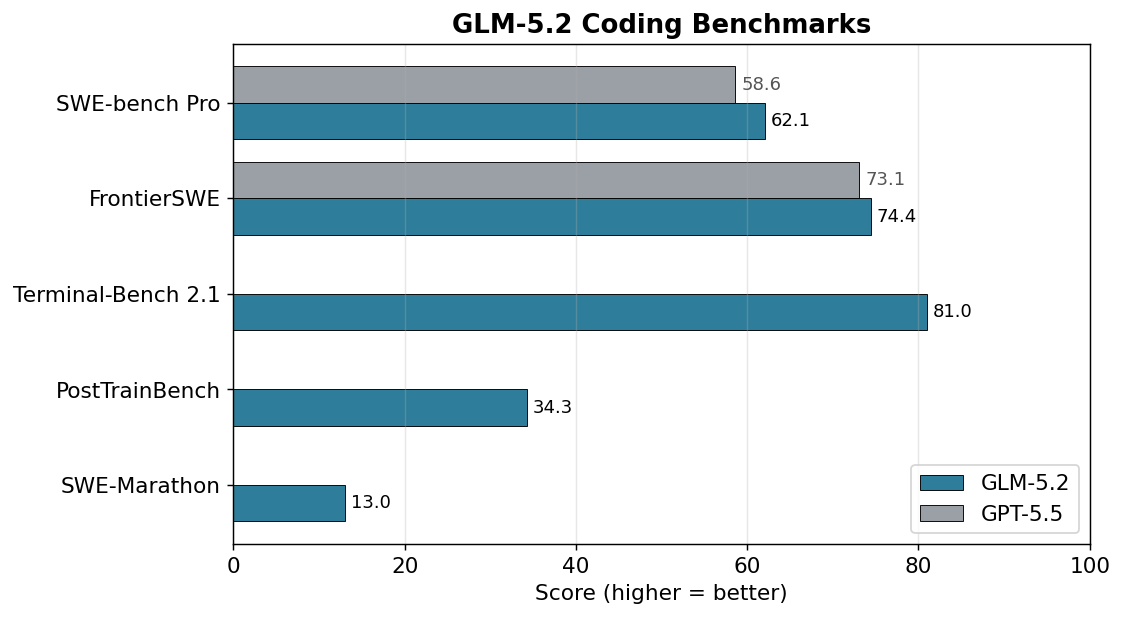
How to read it: GLM-5.2 is the strongest open model on standard coding benchmarks, and the highest open model on long-horizon (multi-step, cross-file) tasks. The weak spot is extreme long-horizon work (SWE-Marathon 13.0%) — covered honestly in the "Who it's for" section below.
GLM-5.2 vs GPT-5.5: Cost and Coding
| Dimension | GLM-5.2 | GPT-5.5 |
|---|---|---|
| SWE-bench Pro | 62.1 | 58.6 |
| FrontierSWE (long-horizon) | 74.4% | 73.1% (Expert-SWE) |
| Context | 1,000,000 | 1,050,000 |
| Price (per 1M tokens) | ~1/6 of GPT-5.5 | $5 in / $30 out |
| Open / self-host | ✅ MIT | ❌ |
| Ecosystem maturity | New, expanding fast | Mature |
Sources: GPT-5.5 specs & pricing · GLM-5.2 benchmarks. Note: both models are in the ~1M context range, with GPT-5.5 (1.05M) slightly larger — GLM-5.2's real edge is cost and open, self-hostable weights, not context length.
This comparison uses publicly reported GPT-5.5 figures; our hands-on case study below uses GPT-5.4, the model currently available on the platform.
Bottom line: for coding and agentic tasks where token cost is a constraint, GLM-5.2 is a strong candidate; for the most mature general-purpose ecosystem, GPT-5.5 still has a place.
Case Study: Running a Real Research Task on GLM-5.2
We ran a direct comparison on SciClaw · Mira: same project, same question, driving the same research agent with GLM-5.2 and then GPT-5.4, to see how each handles a real R&D task.
Task: predict the boiling points of three pentane isomers (n-pentane, isopentane, neopentane) and analyze how branching affects boiling point — via the /material-property-prediction (MPA model) skill.
One honest caveat up front: both sessions call the same MPA prediction backend, so the core predicted numbers are identical (table below). This comparison isn't about "which model is more accurate" — it's about the quality of each model as the agent driver: does it verify, visualize, and explain the result on its own?
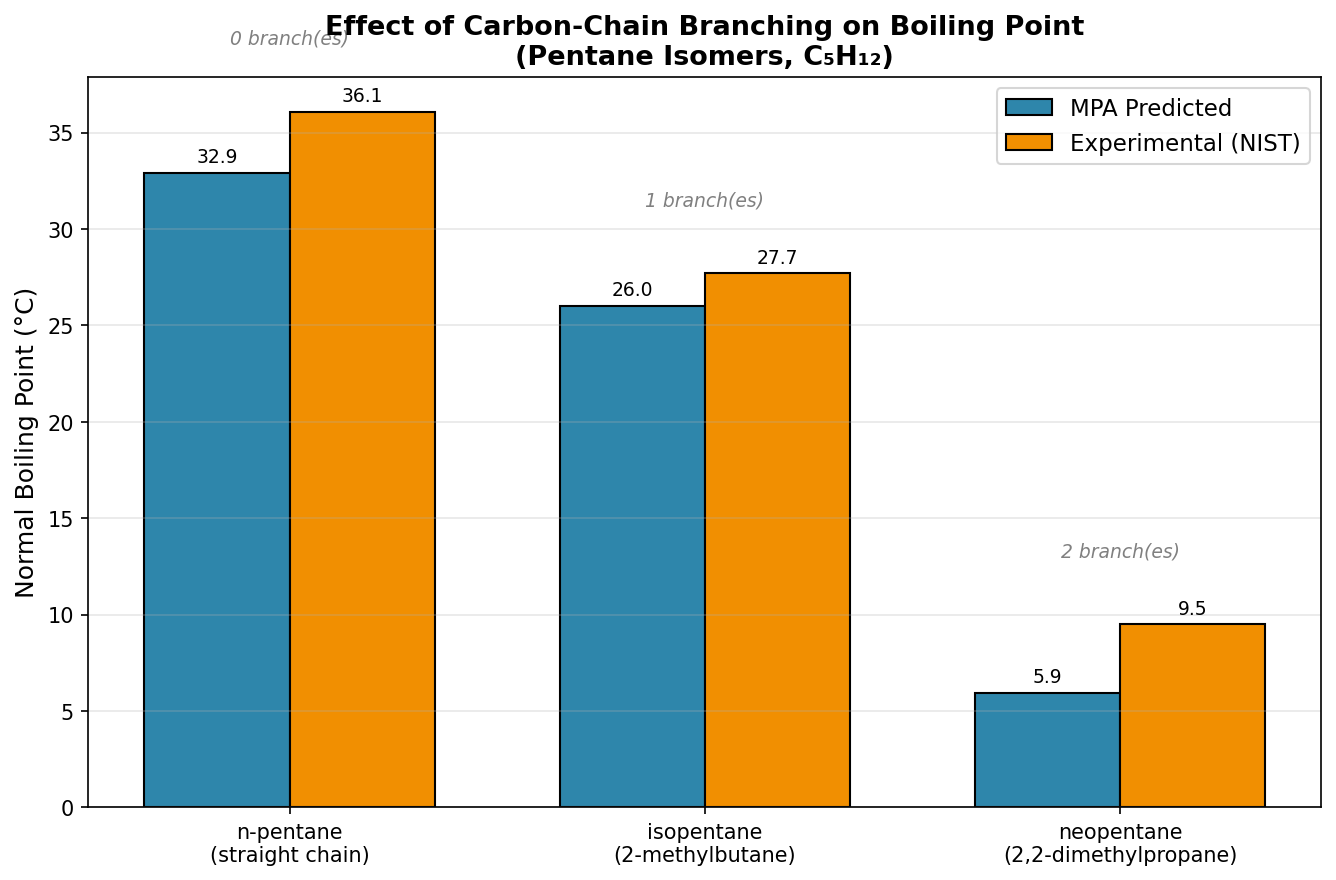
Predicted vs NIST experimental (identical across both models):
| Isomer | Branches | Predicted BP (°C) | NIST exp. (°C) | Error |
|---|---|---|---|---|
| n-pentane | 0 | 32.9 | 36.1 | −3.2 |
| isopentane | 1 | 26.0 | 27.7 | −1.7 |
| neopentane | 2 | 6.0 | 9.5 | −3.6 |
Boiling point falls monotonically as branching increases; total drop n-pentane→neopentane is −27.0 °C predicted vs −26.6 °C experimental (within 0.4 °C).
The difference is in how each model completed the task:
| Metric | GLM-5.2 | GPT-5.4 |
|---|---|---|
| Turns | 7 | 11 |
| Input tokens | 168,613 | 222,843 |
| Output tokens | 3,971 | 1,350 |
| Duration | 118.3s | 134.1s |
| Compared to NIST data on its own | ✅ | ❌ |
| Generated a comparison chart | ✅ | ❌ |
| Physical-mechanism explanation | Detailed | Brief |
- GLM-5.2 proactively compared predictions to NIST experimental values, computed per-isomer errors, generated a comparison bar chart, and explained the physics (branching makes the molecule more spherical, non-linearly shrinking contact area and weakening London dispersion forces). It also did this in fewer turns, with fewer input tokens, and faster.
- GPT-5.4 returned correct predicted values and a brief branching note, but did not compare against experimental data or generate any chart — a leaner output.
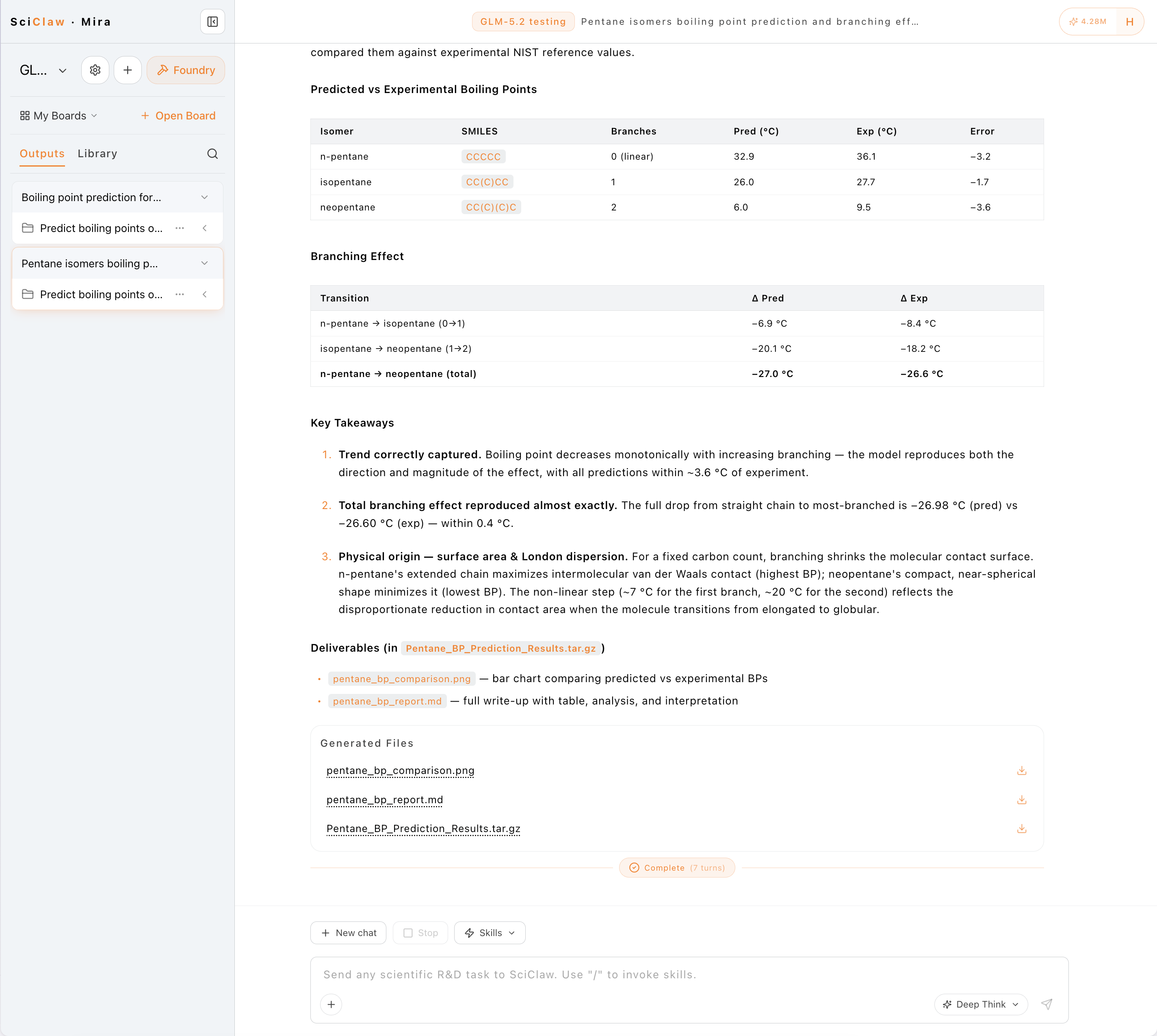
Conclusion (scoped): on this single research task, GLM-5.2 was the more proactive and thorough agent driver, and used fewer tokens — combined with ~1/6 the cost, that's compelling for high-volume research workflows. Note: this is an N=1 single observation, not a systematic benchmark; and the model compared here is GPT-5.4 (what was available on the platform), not the GPT-5.5 used in the benchmark section above.
Want to reproduce it? Run the same task on SciClaw · Mira with free credits. Get started →
Who GLM-5.2 Is (and Isn't) For
Good fit:
- Coding / agentic workflows, especially where token cost matters
- Tasks needing huge single-pass context (large codebases, long docs, research material)
- Teams needing data privacy / self-hosting (MIT weights)
Not (yet) ideal / caveats:
- Extreme long-horizon autonomous tasks still have a gap (SWE-Marathon 13.0%)
- Some independent third-party benchmarks are still rolling out; numbers may update
- For the most mature general-purpose ecosystem, closed flagships still lead
FAQ
Is GLM-5.2 free? The model itself is MIT open source and free for commercial use. For cloud access, SciClaw · Mira gives you free credits to use it with zero setup; platforms like Z.ai also offer trial credits.
Do I need an API key to use GLM-5.2? Not necessarily. On SciClaw · Mira you use free credits — no API key, no code. You only need a key if you connect directly to the official API.
Can I use GLM-5.2 commercially? Yes. The MIT license permits commercial use, modification, and private deployment.
How large is GLM-5.2's context window? Up to 1,000,000 tokens — about 5× the previous generation.
Is GLM-5.2 better than GPT-5.5? It wins on several long-horizon coding benchmarks at ~1/6 the cost; GPT-5.5 still leads on general-purpose ecosystem maturity.
What are GLM-5.2's coding benchmark scores? SWE-bench Pro 62.1, Terminal-Bench 2.1 81.0, FrontierSWE 74.4% — top-tier open source.
Can I run GLM-5.2 locally?
Yes — weights are on Hugging Face (zai-org/GLM-5.2); you'll need your own GPU. See our local deployment guide.
Where can I try GLM-5.2 free fastest? SciClaw · Mira — sign up for credits and use it in your browser instantly.
Want to verify it yourself? Use free credits on SciClaw · Mira to run GLM-5.2 — no key or setup — and test the scenarios above in your own agent. Get started →